
There is more value in your data
Have a feeling your data contains more insights and value than you extract from it?
It may be so.
If your data is highly connected and you are not using graphs and graphs algorithms then the likelihood for it is higher.
In this post, I will try to show what data on a graph looks like and how by setting very simple inference rules and binding them together, complex and far-away insights suddenly emerge in the places you need actually them. As a post without an AI mentioned in it is “unacceptable” today I will conclude this with a short discussion of how this can:
- Reduce the costs of training our ML models
- Improve your AI accuracy (as a general term not specifically the measure)
I will try to make this article visual, simple, and clear, and I hope reading it will be interesting and fun.
First things first
Much has been (and will be) discussed on the benefits of graph data, so I will just start by putting forward the following image from Gartner about the impact of Knowledge Graphs on Generative AI and the following quote:
Knowledge graphs and scalable vector databases are key software enablers. These technologies are supporting generative AI adoption by improving the explainability and utility of LLM implementations within the organization. Investment in these technologies will be important for GenAI adoption.
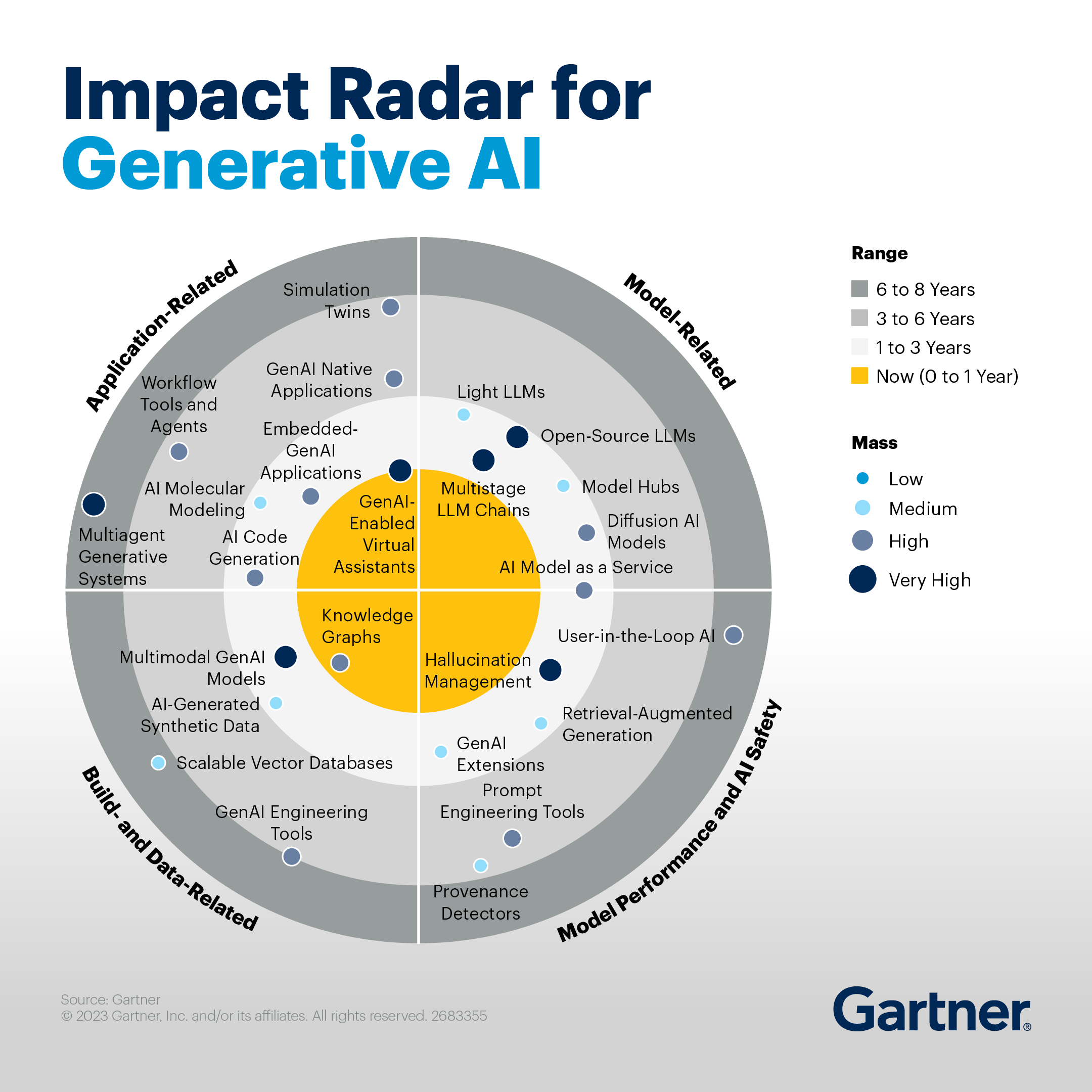
As can be seen, Knowledge Graphs are in the central part and have a high mass, which means the technology already has a high impact. It also means that if you are currently developing or planning to develop a solution that uses generative AI and not using Knowledge Graphs then starting to look into the subject may be a good opportunity (you are welcome to share your challenge and let’s discuss if UnfogIt can help you).
What are inference rules?
Not all graph databases are made equal. The are multiple graph databases in the market and each has its strengths and weaknesses. Choosing the best solution depends on your specific problem and goals. Here I will focus on TypeDB which has a few unique capabilities that I enjoy working with. Among these capabilities, I will focus in this post on inference rules.
”Inference rules” might mean different things to different people, so let’s define what we’re talking about. In this context, I’m referring to a form of simple, deterministic, and explainable logic. A classic example is transitivity: if X is part of Y and Y is part of Z, then X is part of Z. This logic underpins part of ShareIt, a customizable solution offered by UnfogIt.
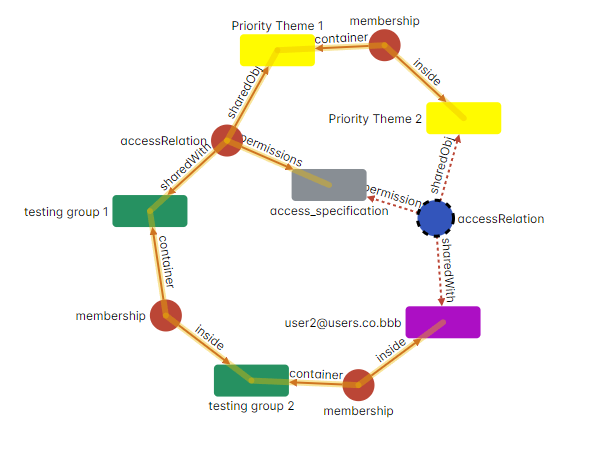
To bring this concept to life, let’s consider a scenario involving ShareIt. We query which groups user2 belongs to. The findings reveal that user2 is directly a member of “testing group 2” and, through inference, also part of “testing group 1”.
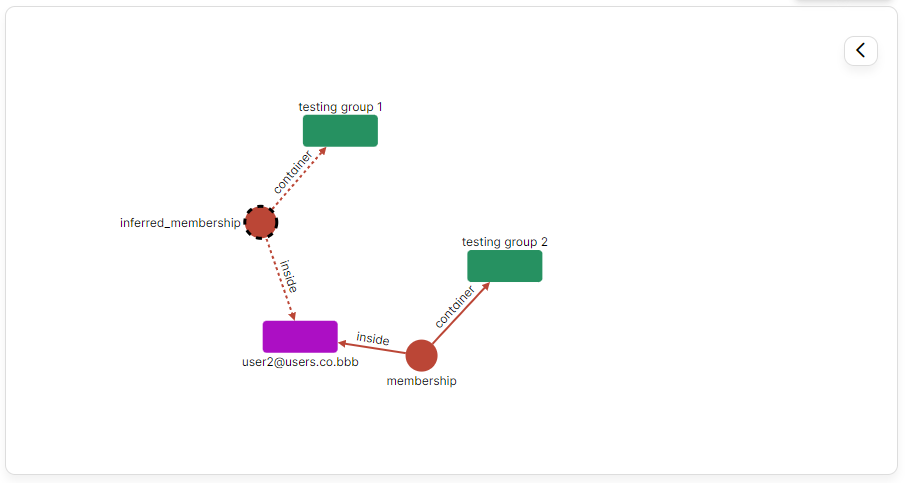 Choosing the inferred relation and asking it to explain it, will result in the following:
Choosing the inferred relation and asking it to explain it, will result in the following:
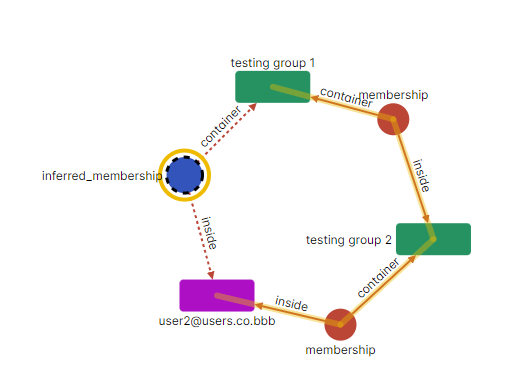 Showing “testing group 2” contained inside “testing group 1” and therefore the inferred relation was created.
Showing “testing group 2” contained inside “testing group 1” and therefore the inferred relation was created.
This is the exact implementation of transitivity and can be extended as rules can be deduced based on conclusions from other rules. Therefore, if we continue this simple example we can see that user9 is a direct member of “testing group 9” but also has membership in each group “testing group 9” inside through inference.
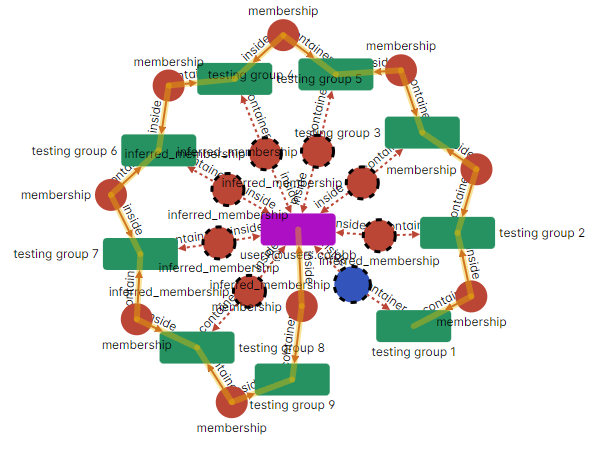
In ShareIt, the concept of embedding objects within tags or contexts takes this idea a step further. These tags or contexts can also be nested within each other, following a similar logic through rules. This setup allows ShareIt to manage permissions effectively. Take, for example, user2’s access to “Priority Theme 2.” Whether it represents a file, a document section, an API endpoint, or any other resource, the permissions are dynamically inferred to it.
What makes this particularly powerful is the efficiency of the process. These permissions are determined and applied quickly (typically without the need for visualization shown here). This ensures that ShareIt can manage complex permission structures swiftly and accurately.
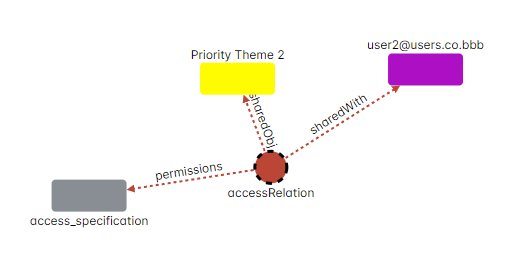 Asking for explanation results with the following explanation in which “testing group 1” was given permission to “Priority Theme 1” and all the rest derived from that.
Asking for explanation results with the following explanation in which “testing group 1” was given permission to “Priority Theme 1” and all the rest derived from that.
 In a bit more complex example for the biology domain (using the LinkML data model). Asking for all the chemical entities related to a specific protein will result with:
In a bit more complex example for the biology domain (using the LinkML data model). Asking for all the chemical entities related to a specific protein will result with:
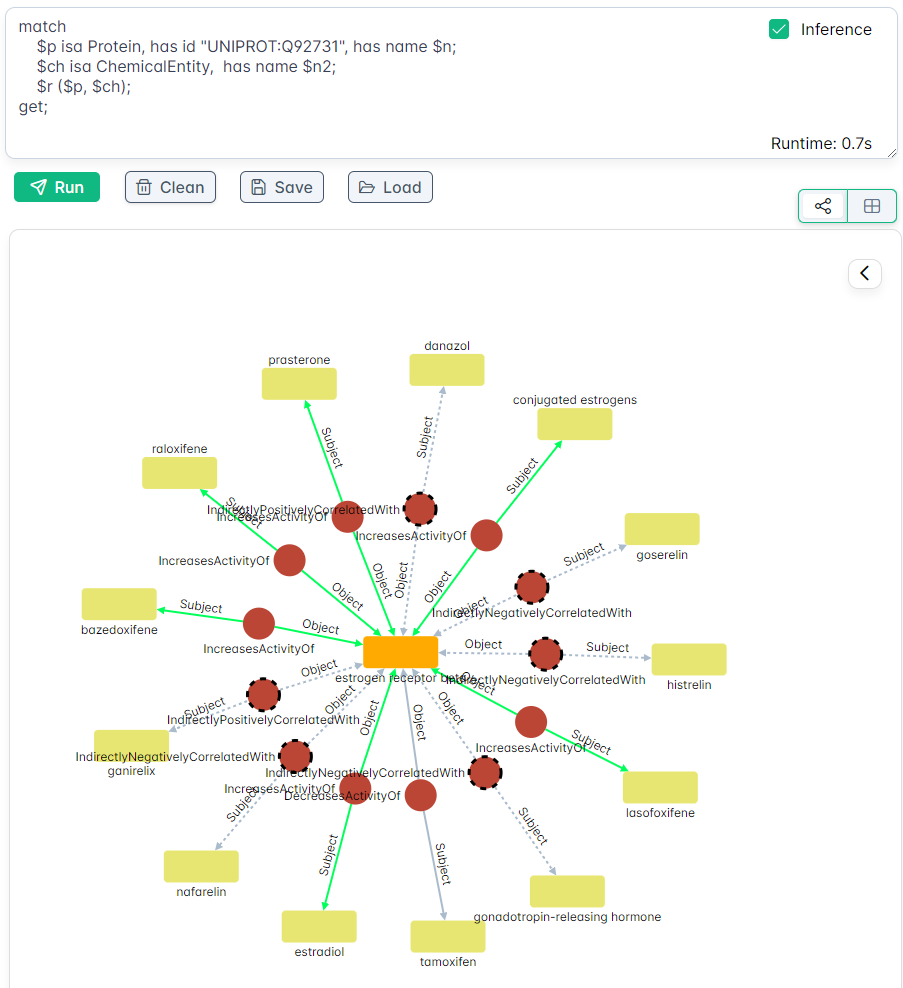 ⚠️ Please note that the protein and the following chemical compound selection were chosen randomly.
⚠️ Please note that the protein and the following chemical compound selection were chosen randomly.
Consider a scenario involving a chemical entity named nafarelin, which is found to be indirectly negatively correlated with a specific protein in our system. When we probe the system to uncover the reason behind this indirect negative correlation, it provides us with an insightful explanation.
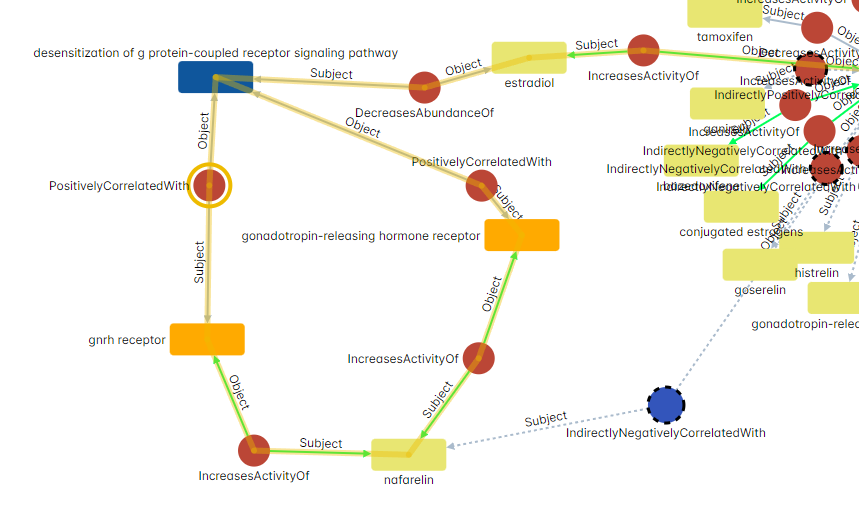 This example shines a light on the sophisticated interplay of rules managing complex interactions, where entities are mostly positively correlated except for a single step within the explanation path. The simplicity of the rules belies their power: they adeptly consider this variance, ensuring accurate interpretations. This mechanism remains robust even when faced with multiple negative correlations along a path, adeptly ‘flipping’ the interpretative stance with each shift in correlation.
This example shines a light on the sophisticated interplay of rules managing complex interactions, where entities are mostly positively correlated except for a single step within the explanation path. The simplicity of the rules belies their power: they adeptly consider this variance, ensuring accurate interpretations. This mechanism remains robust even when faced with multiple negative correlations along a path, adeptly ‘flipping’ the interpretative stance with each shift in correlation.
The benefits of inference rules
This series of straightforward, visual examples has illustrated the power of rules in data exploration. We’ve seen how, with the right rules in place, the data we seek is easily accessible through simple queries. It is important for every analyst to look into the data manually. But with an excellent analyst who has enough domain knowledge, time, and willingness to drill down every possible path these insights will be available. When it comes to automated processes or machine learning the far-away data becomes out of reach in most cases. Even when utilizing graph algorithms they still define a computation graph as shown below.
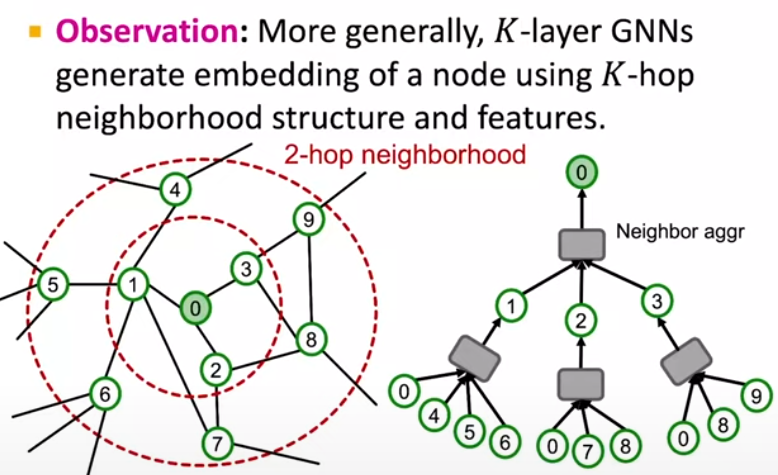 The image was taken from Stanford CS224W -Lecture 17.2 (3:20)
The image was taken from Stanford CS224W -Lecture 17.2 (3:20)
This computation graph tends to rapidly grow as we search for data that is further away (increasing k) and therefore are usually limited to a small number making far away, yet imported, data out of reach. Then, even is the relevant data is within reach its value most likely “fades” through the distance. Implementing rules strategically can mitigate this issue by effectively ‘bringing closer’ the data that matters most. This approach not only enhances performance and explainability but also allows for a more compact computation graph. Consequently, this leads to more efficient training processes, as the significant data is made readily accessible without the need for extensive computational overhead.
Few additional notes
Stay tuned for many cool features and integrations that are in it's roadmap.